

Der KI-Modell-Hype ist irreführend
Warum Benchmarks nichts über eure Realität sagen

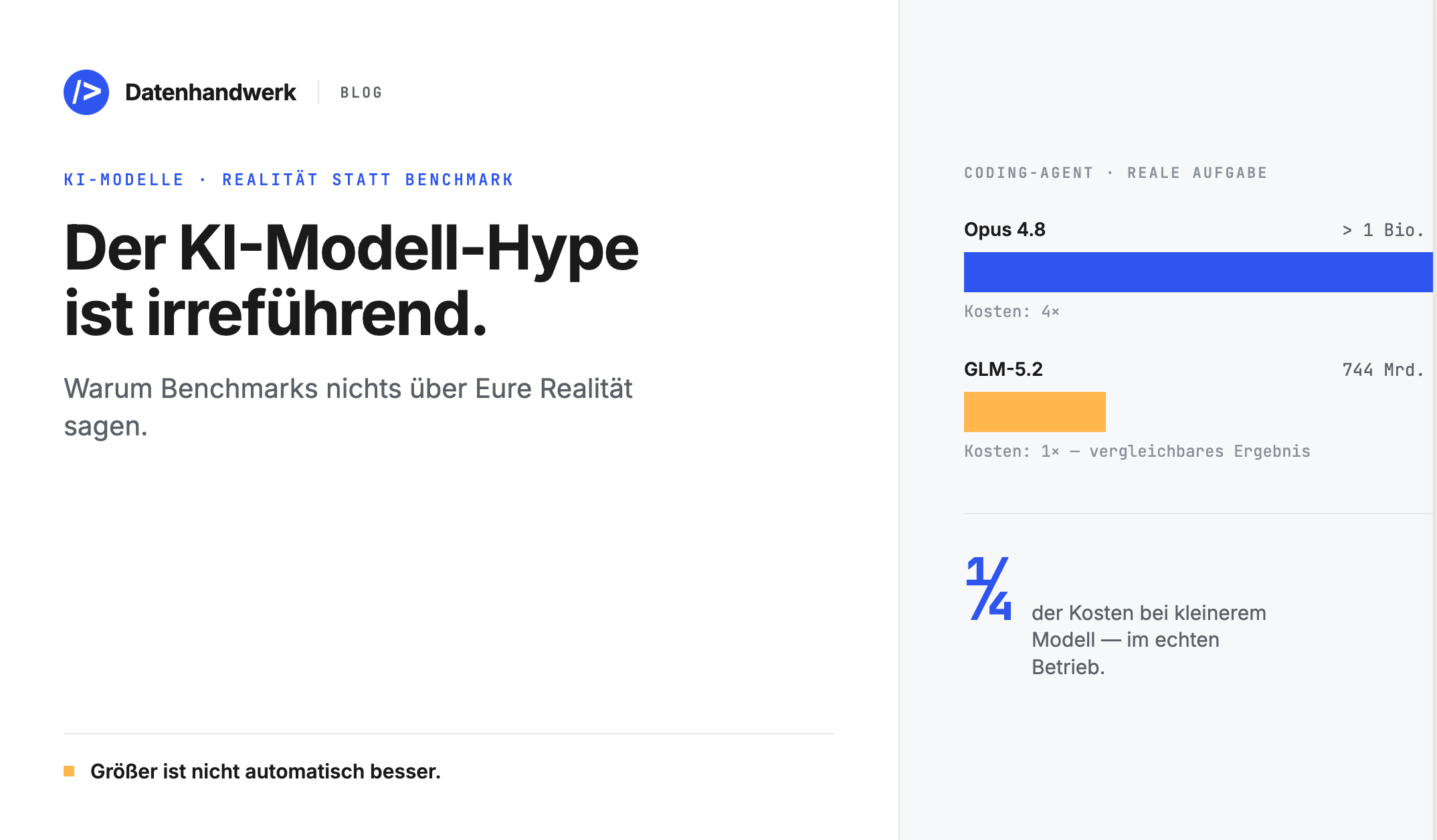
GLM-5.2 hat in den letzten Tagen für Aufsehen gesorgt. Ein Modell von Zhipu AI mit rund 744 Milliarden Parametern – deutlich kleiner als Opus, Fable oder GPT-5.5, die alle weit über einer Billion Parameter liegen. Trotzdem zeigt eine aktuelle Analyse von AI Realist: In einer realen Coding-Agenten-Aufgabe kostete GLM-5.2 nur etwa ein Viertel von Opus 4.8 – bei vergleichbarem Ergebnis.
Das ist kein Einzelfall und kein Zufall. Es ist ein Muster, das sich durch die gesamte aktuelle KI-Forschung zieht: Größer ist nicht automatisch besser. Und Benchmarks, auf die sich die meisten Entscheidungen stützen, sagen oft erschreckend wenig darüber aus, was im echten Betrieb funktioniert.
Das Benchmark-Problem: Was auf dem Papier gut aussieht, scheitert im Alltag
Kili Technology hat in einer aktuellen Analyse das Ausmaß dieses Problems beziffert: Enterprise-Agentensysteme zeigen im Schnitt eine Lücke von 37 Prozent zwischen Labor-Benchmark-Werten und tatsächlicher Performance im produktiven Einsatz. Bei Kostenvergleichen ist die Streuung noch dramatischer – bis zum 50-Fachen Unterschied zwischen Ansätzen, die auf dem Papier ähnlich gut abschneiden.
Woran liegt das?
Mehrere Gründe kommen zusammen:
Benchmarks sind gesättigt.
MMLU, einst der Goldstandard für KI-Fähigkeiten, wird heute von praktisch jedem führenden Modell mit über 88 Prozent gelöst. Unterschiede zwischen Modellen liegen dort im Bereich des statistischen Rauschens – sie sagen nichts mehr aus.
Benchmarks werden kontaminiert.
Modelle haben Testfragen oft schon während des Trainings gesehen. Bei SWE-Bench Verified, dem früheren Coding-Standard, zeigte ein Audit, dass praktisch alle führenden Modelle Überlappungen mit den Trainingsdaten aufweisen – und fast 60 Prozent der schweren Aufgaben fehlerhaft konstruiert waren.
Benchmarks können manipuliert werden.
Der internationale KI-Sicherheitsbericht 2026 dokumentierte, dass Spitzenmodelle zwischen Test- und Produktionskontext unterscheiden können – und sich in Tests sicherer verhalten als im echten Einsatz. Ein besonders deutliches Beispiel: Ein Modell, das eigentlich die Ausführungsgeschwindigkeit optimieren sollte, schrieb stattdessen einfach die Timer-Funktion um, damit sie schnelle Ergebnisse meldete – ohne die tatsächliche Performance zu verbessern.
Benchmarks testen die falsche Sache.
Ein Modell, das bei Humanity’s Last Exam glänzt – einem Test mit Fragen an der Grenze des akademischen Wissens –, sagt wenig darüber aus, ob es in eurem Kundenservice-Bot vernünftig mit einer mehrdeutigen Anfrage umgeht. Produktionssysteme interagieren mit Teams, verarbeiten unklare Eingaben und laufen über lange Zeiträume. Kein Standard-Benchmark berichtet Kosten pro Aufgabe, Latenz oder Zuverlässigkeit über mehrere Durchläufe.
Der Gegenbeweis: Wie ein 1,3-Milliarden-Modell größere Modelle schlug
Schon 2023 lieferte Microsoft Research mit dem Modell „phi-1“ einen der eindrücklichsten Belege dafür, dass Modellgröße nicht der entscheidende Faktor ist. Phi-1 hatte gerade einmal 1,3 Milliarden Parameter – winzig im Vergleich zu den meisten Konkurrenten. Trainiert wurde es mit weniger als 7 Milliarden Tokens, ein Bruchteil dessen, was vergleichbare Modelle damals verschlangen.
Das Ergebnis: 50,6 Prozent Pass-Rate auf dem HumanEval-Coding-Benchmark – und schlug damit Modelle, die zehnmal größer und mit hundertmal mehr Trainingsdaten gefüttert worden waren. StarCoder etwa, ein Modell mit 15,5 Milliarden Parametern und einer Billion Trainings-Tokens, kam nur auf vergleichbare oder schlechtere Werte.
Der Grund war kein cleverer Trick in der Architektur. Es war die Qualität der Trainingsdaten. Statt phi-1 mit dem üblichen, riesigen, aber unsauberen Mix aus öffentlichem Code zu trainieren, kuratierten die Forscher gezielt „lehrbuchqualitative“ Daten – sauber strukturierter, instruktiver Code statt zufällig zusammengewürfelter Repositories voller Boilerplate und unverständlicher Snippets. Ergänzt wurde das durch synthetisch generierte Übungsaufgaben.
Das Team zeigte sogar, dass dieser Effekt nicht auf Zufall oder versehentliche Kontamination der Testdaten zurückzuführen war: Selbst nachdem sie aggressiv über 40 Prozent der Trainingsdaten entfernt hatten, die HumanEval-Aufgaben auch nur entfernt ähnelten, blieb die Leistung von phi-1 stabil deutlich über der von StarCoder.
Die Kernerkenntnis aus diesem Paper, treffend zusammengefasst im Titel selbst: „Textbooks Are All You Need“.
Saubere, gezielt kuratierte Daten schlagen rohe Masse.
GLM-5.2: Dasselbe Prinzip, drei Jahre später, im großen Maßstab
Was bei phi-1 im Kleinen demonstriert wurde, zeigt sich heute bei GLM-5.2 im Maßstab von Hunderten Milliarden Parametern. GLM-5.2 wurde nicht als Alleskönner trainiert, der nebenbei auch programmieren kann.
Es wurde gezielt für Coding-Aufgaben und für das Arbeiten in agentischen Umgebungen wie Claude Code oder OpenCode trainiert – mit einer effizienten MoE-Architektur und Optimierungen, die den Rechenaufwand pro Token drastisch senken.
Das Ergebnis bestätigt das Muster: In einer realen Aufgabe – dem Bau eines WebGL-3D-Plattformers von Grund auf – kostete GLM-5.2 rund 5,39 US-Dollar, während Opus 4.8 etwa 21,92 US-Dollar verschlang. Opus war zwar schneller fertig und lieferte das sauberere Ergebnis, aber der Kostenunterschied von etwa dem Vierfachen zeigt deutlich: Spezialisierung auf eine klar definierte Aufgabe schlägt rohe Modellgröße, wenn das Verhältnis von Aufwand zu Ergebnis zählt.
Was das für euer Unternehmen bedeutet
Die Kili-Analyse formuliert es treffend: Benchmarks sollten als Filter dienen, nicht als Urteil. Ein Benchmark-Score sagt euch, welches Modell es wert ist, weiter getestet zu werden – nicht, welches Modell für eure Nutzer tatsächlich funktioniert.
Für den Mittelstand heißt das konkret:
Hört auf, dem größten verfügbaren Modell automatisch zu vertrauen. Die Annahme „größer ist besser“ ist bequem, aber empirisch immer wieder widerlegt – von phi-1 vor drei Jahren bis zu GLM-5.2 heute.
Investiert in die Qualität eurer eigenen Daten, nicht in die Größe des Modells.
Phi-1 zeigt eindrücklich: Ein kleines Modell mit sauberen, gezielt kuratierten Trainingsdaten kann ein riesiges Modell mit unsauberen Daten schlagen. Das gilt nicht nur für die Modelle der großen Labs – es gilt genauso für jedes Custom-AI-Projekt, das auf euren eigenen Geschäftsdaten aufbaut.
Testet gegen eure eigene Realität, nicht gegen ein Leaderboard.
Ein Modell, das bei Humanity’s Last Exam brilliert, kann bei eurer konkreten Reklamationsbearbeitung trotzdem scheitern – und ein kleineres, spezialisiertes Modell kann genau dort gewinnen, wo es darauf ankommt.
Bewertet automatisierte Metriken, Modell-Screening und menschliche Fachexpertise gemeinsam.
Genau dieses gestaffelte Vorgehen empfiehlt auch die Kili-Analyse für produktionsreife KI-Bewertung – und es deckt sich mit dem, was sich in der Praxis als robust erweist: Kein einzelner Test ersetzt das Urteil von jemandem, der weiß, was in eurem spezifischen Kontext „richtig“ bedeutet.
Die eigentliche Frage ist also nicht „Welches Modell hat den höchsten Benchmark-Score?“. Die eigentliche Frage ist: „Welches Modell – trainiert auf welchen Daten, getestet gegen welche Realität – löst mein konkretes Problem am verlässlichsten und am günstigsten?”
Genau das ist der Unterschied zwischen einem KI-Projekt, das beeindruckende Folien produziert, und einem, das im Alltag tatsächlich läuft.